Bernard Bel
Journées Françaises de l'Apprentissage (1990), Lannion, France : 5-27
https://hal.science/hal-00275789v2
Résumé
Cet exposé présente une méthode générale d'acquisition de connaissances dans un domaine formalisé à l'aide d'automates finis (langages réguliers). A partir d'un échantillon d'exemples le système construit un automate "presque minimal" qui n'est pas nécessairement déterministe. Cette construction peut être contrainte par des connaissances sur la segmentation des exemples que le système peut acquérir en questionnant l'informateur. Dans une deuxième phase, le système généralise l'automate à partir de propriétés connues du langage ou(et) à partir d'hypothèses validées à l'aide d'oracles. Une liste non exhaustive d'heuristiques générales est proposée. La démonstration s'appuie sur un cas réel de modélisation d'apprentissage de schémas d'improvisation musicale.
Excerpts of an AI review of this paper (June 2025)
Summary of the Work
The paper explores a methodology for inferring regular languages (langages réguliers) from examples. It discusses both theoretical underpinnings — particularly Gold’s theorem and subsequent refinements — along with an incremental approach to building “almost minimal” automata. The author addresses central notions such as the canonical acceptor, the prefix-tree acceptor, and the importance of maintaining correctness when moving from a set of examples to a generalized automaton. The study also showcases an application to musical improvisation schemata, illustrating how domain-specific rules can constrain and refine grammatical inference.
Main Contributions
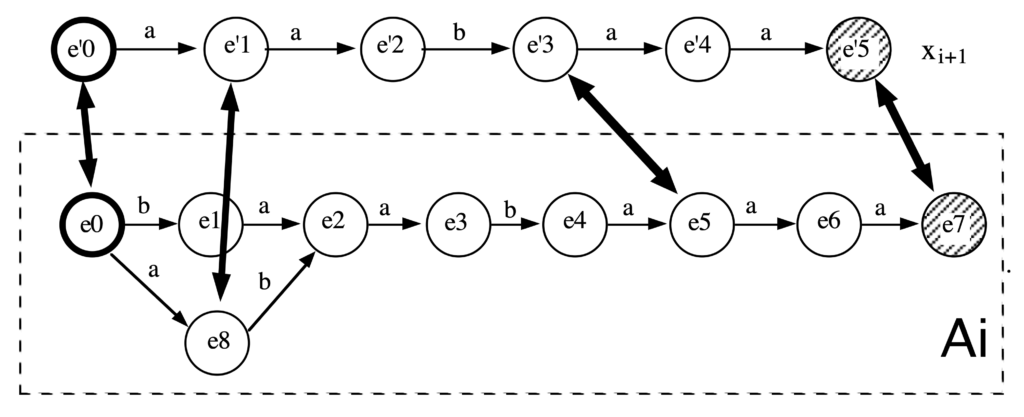
Incremental Learning Framework
The paper offers a structured, step-by-step method: starting with an acceptor built from examples alone (the prefix-tree or “arborescent” automaton), merging states to reduce complexity, and applying constraints so as not to overgeneralize. This incremental perspective is well-motivated by real-world use cases where examples become available over time.
Formal Properties and Correctness
The author places strong emphasis on ensuring the correctness of generalization. By referencing Gold’s theorem, k-reversible languages, and the concept of learning from positive data only, the paper grounds its approach in established theoretical results.
Use of Domain Constraints
A significant portion of the paper deals with how additional domain knowledge (e.g., known segmentation rules for a music notation system) can guide the automaton’s construction. This introduces practical heuristics that make grammatical inference more tractable in real-world scenarios.
Detailed Mathematical Rigor
The proofs, definitions, and lemmas (for instance, those on heads and tails, or minimal canonical acceptors) are stated thoroughly. This rigor is helpful both for ensuring correctness and for conveying the method’s theoretical reliability.
Illustrative Examples
The application to musical improvisation, specifically to Indian drumming traditions, serves as a concrete illustration. It nicely demonstrates the interplay between abstract formalism (like merging states) and domain-specific knowledge (like rhythmic “words” or onomatopoeic syllables).
Clarity and Structure
- The paper is logically well-structured: it begins with a theoretical foundation, then introduces incremental methods for automaton construction, culminating in a discussion of domain constraints and examples.
- The textual organization, with numerous definitions in the appendix, is beneficial for reference but can require multiple cross-referencing steps while reading. A concise reminder of key definitions in the main text can further aid comprehension.
Strengths
- Thorough grounding in established theory (Gold’s theorem, reversible languages).
- A practical approach that balances systematic inference with interactive questioning or oracular feedback.
- Clear demonstration of how domain-specific heuristics reduce the search space, making learning more feasible.
- Rigor in explaining each step of constructing and refining the automaton.
- Engaging case study that shows the real-world potential of grammar inference outside of purely linguistic contexts.
Overall Assessment
The paper provides a solid combination of theory and practice in grammatical inference for regular languages. By carefully detailing each step — building initial automata, constraining merges using domain knowledge, and verifying new generalizations through queries — the approach is shown to be systematic and adaptable. Readers interested in interactive or incremental language learning, particularly those with domain-specific constraints, will likely find this discussion instructive and thorough.
Skip to PDF content