In a previous article we explained how to install and run the Bol Processor ‘BP1’ on a virtual Apple IIe. BP1 is the earliest version of Bol Processor implemented on Apple II computers in 1981, as a requirement for Jim Kippen’s fieldwork in India — see At the heart of Indian rhythms and their evolution.… We will now show its operation in a real musical context: the modelling of a 'theme-and-variations' piece of drumming (called q‘aida) taught by Ustad Afaq Husain Khan, an expert in the Lucknow style of tabla in India.
This work dates back to the 1980s and has been documented in several publications, including Kippen and Bel's Modelling music with grammars: formal language representation in the Bol Processor (1992), from which the example will be taken. Extract (page 207):

A large part of the tabla repertoire is improvisation. Any sequence of strokes can be seen as a finite string of symbols whose organisation is related to an implicit formal system. Automatic sequences (i.e. sequences generated by finite-state automata) have properties that place them somewhere between periodicity and chaos, but closer to periodicity. Since both strict and approximate periodicity are essential features of music, it is realistic to think that sequences of musical events can be adequately represented by automata or formal grammars. In other words, the most fundamental reason for us to consider formal language models as relevant models of music lies in properties that are intrinsic to music, rather than in analogical links between music and natural languages.
The theme of this q‘aida is the following sequence:
| dhatidhage | nadhatrkt | dhatidhage | dheenagena |
| dhatidhage | nadhatrkt | dhatidhage | teenakena |
| tatitake | natatrkt | tatitake | teenakena |
| dhatidhage | nadhatrkt | dhatidhage | dheenagena |
Strokes on the drum — bols like 'dha', 'ti', 'ge', 'na'… — belong to the (terminal) alphabet of the formal grammar. This sequence should be read linearly from left to right. Each group represents a beat of 4 units ('trkt' is a compound stroke of 2 units). Thus, the theme and its variations are framed on a 16-beat rhythmic model called tintal in North-Indian music.
The grammar and examples of this qa‘ida are stored as "Q2.7" on disc "BP-JULY87.DSK" which can be loaded after starting the Bol Processor (BP-PRG.DSK). We recommend that you set the virtual Apple II to maximum speed to save time when reading (virtual) discs! After loading the Q2.7's grammar and data, the theme can be displayed as data item #2:
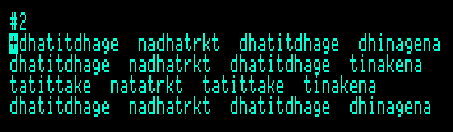
Note that the terminal alphabet used on BP1 is not exactly the same as in the publication. For example, 'dhee' has been replaced by 'dhi', 'tee' by 'ti', substantial changes for readers who prefer a transliteration of Hindustani phonemes to the rendering of syllables in English.
In addition, syllable 'ti' can be rendered as 'tit'. These subtleties are governed by the keyboard mapping, which can be viewed (and modified) by selecting "Alphabet" then "Modify" from the main menu.
The grammar implemented in BP1 is the same as that shown in Appendix 2 of the publication, except for spelling variants of some bols and different glyphs used to mark patterns - "master" and "slave" markers, see our Pattern grammars article — and the bol density instruction, as explained in a previous article. For example, the rule
GRAM#2 [20] <100> S32 <—> * (= /6+ A16 V8 + /4) + O16
was displayed as:
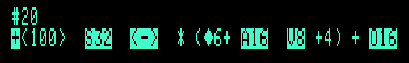
The bol density marker "6" is now written as "/6" and "4" as "/4". The plus sign '+' is used as a context marker.
In later versions of the Bol Processor, we created a "_tempo()" tool which is more flexible than bol density. For example, "_tempo(8)" would have the same effect as "/8" in a simple sequence. However, in polyphonic structures, "/8" is an absolute value whereas "_tempo(8)" is relative to the current tempo. This makes it possible to calibrate the durations of several sequences contained in a polymetric expression — see Two Algorithms for the Instantiation of Musical Structures (1994) for details. Furthermore, expressions such as "_tempo(7/4)" and even "_tempo(0.476)" are permitted…
Templates
Subrammar #7 contains the templates of this grammar:
[1] TEM
[2] (=+.….….….…+.….….….…+ * (=+.….….….…+) +.….….….…;)
[3] (=+.….….….…+.….….….…+ * (=+.….….….…+) +/8+.….….….….….….….…;/4;)
[4] (=+.….….….…+.….….….…+ * (=/6+.….….…/4.….…+) +.….….….…;)
etc.
These templates are the complete list of patterns produced by (presumably) all variations of the q‘aida. They contain parentheses surrounding reference strings with the "=" marker (displayed as "◆" in BP1), bol density numbers, and arbitrary "+" and ";" symbols used as context in the rule, as explained in the publication. Technically, patterns are similar to regular expressions against which a variation is checked before being parsed by the grammar.
Any grammar that contains patterns and/or bol density figures must be supplemented with templates in order to assess the grammaticality of variations. Fortunately, these templates are automatically generated by the grammar!
Producing items
To create variations based on this grammar, select "Grammars" from the main menu, then go to subgrammar #1, "Edit", and move to rule #2, for example:
<100> S <—> (=+ S64 ;)
This will produce variations of 64 bols as suggested by the name of the variable "S64". Rule #3 would produce variations of 128 bols as suggested by "D128".
Type ctrl-C ([C]ompute). You will be asked to specify the first subgrammar (1) and the last subgrammar (6). For example, if you are starting to compute from a rule of subgrammar #3, it makes sense to specify #3 as the first subgrammar. If a subgrammar lower than 6 is specified as the last, some variables may not be rewritten as strings of terminal symbols. This can be useful for checking sub-processes in the production of variations.
The options offered are A)nalyse, S)ynthesize, D)estroy structure and Q)uit. Select "Synthesize". Say 'no' to "Create templates" and "Systematic tree-search". You may answer 'yes' to "Step by step?" to see all the derivation steps, so you can familiarise yourself with the grammar. Example of a result:

This is an interesting example: in the third line, the bol density is doubled (8 instead of 4).
You are now offered the option to "Append" the variation to the data set, "Repeat" the production process, "Print" (on the virtual printer), create "More" variations or "Verify" this variation. It is not obvious that the grammar will accept this variation if it is poorly designed. (This is unlikely in this example.) The "Verify" option should quickly end up with "S", the start string, if the variation is correct.
If some variations have been added to the data set, editing Data will display them at the end of the set.
This process of producing variations is called "modus ponens" in expert systems jargon. Variations produced in this way were read by the analyst (Jim Kippen) to the expert musician to check their acceptance as legitimate variations of the q‘aida.
Analyzing variations
Now imagine the expert musician playing a variation that is typed into the data set. It is clear that fast and accurate typing was crucial to this field research… Use keyboard mapping to learn to type at high speed; it is less difficult than playing the drums!
When a variation is displayed in the data set, type ctrl-C for "[C]ompute". Answer 'yes' to "Revise processing?". Now the first grammar is #1 but the last grammar should be #7 so that templates are taken into account. Select "Analyse", say 'no' to "Display probability?" and 'yes' or 'no' to "Step by step?".
If you are analysing step by step, use the right arrow to go forward or the left arrow to go back. The subgrammar currently used for derivations is shown at the bottom of the page, and the index of the latest candidate rule appears at the top. In this way it is possible to visualise all the details of the calculation for the production or analysis of a variation.
You can check the entire data set against the grammar by selecting "Verify grammars" from the main menu.
If the variation matches more than one template, each template is used to parse it. If the parsing is successful with multiple templates, the structure of the piece is ambiguous. This is analogous to parsing the sentence "Mary said John is a liar", which requires the placement of either two commas or a semicolon, with each "template" giving an opposite meaning…
Weights
Currently, in the grammar, all rule weights are set to 100 except for rule #3 of subgrammar #1. We can use the 12 variations in the data set to infer rule weights: each of them is analysed and each rule has its weight increased by 1 unit.
Select "Weights" from the main menu, then "Emulate learning" and "Reset weights to 0". From item #2 to item #13. The last grammar is "7" (as templates are required).
The result can be printed. Note that all weights in subgrammar #6 are set to 100 because it is an "ORD" grammar: no random selection of the candidate rule.
The input of new data sets allowed "learning" from more examples and improving the stochastic model, which would produce more "aesthetically acceptable" variations.
Intermediate alphabet
Accessed from the main menu. This procedure is used to changie the names of variables. This procedure has proved useful in creating grammars that make sense to humans, not just machines…
Creating templates
To check this, it is recommended to quit and reload the current project, as some procedures may have been saved in memory. Load only the grammar, no data, to keep enough free memory.
Select "Grammars" from the main menu, then go to subgrammar #7 (the current templates) and delete it by selecting "Remove from series". (This may not be necessary as the machine never duplicates a template, but it makes things clearer.)
Then create a new subgrammar #7, select "Compute" and "Create templates". You will be asked for the "last grammar defining structures". This choice is very important for the speed of the computation, because the production of templates implies the production of "all variations". If your answer is "6", the machine can work extremely long. Looking at the grammar, we can see that subgrammar 3 is the last to contain structural markers. So the correct answer is "3".
This process takes a long time, even at the highest speed. Its progress is indicated by '+' signs printed on the line below 'WAIT'. Since this grammar produces 21 templates, you have to wait for 21 '+' signs. Fortunately, in most grammars, the generation of templates is done once and for all…
Conclusion
This demo is an attempt to illustrate the use of the Bol Processor BP1 in the early 1980s as an expert system for modelling compositional/improvisational processes in the q‘aida genre of tabla drumming. Of great importance was the development of an editor that facilitated the rapid and accurate writing of bols (representations of drum strokes) and the creation of pattern rules that took into account the implicit syntactic structures of these musical pieces.
Later, the Bol processor was implemented on Macintosh computers. Versions of 'BP2' compatible with system versions up to MacOS 10.14 (Mojave) can be dowloaded from SourceForge.
BP2 reproduces all the procedures of BP1, in particular those described in Kippen & Bel's paper Modelling music with grammars: formal language representation in the Bol Processor (1992). However, its editor is not as sophisticated in terms of pattern editing. Also, the "smart keyboard" option allows terminal symbols to be mapped to individual keys, but the cursor does not "jump" over terminal symbols, variables and reserved words.
BP2 introduced the possibility of polyphonic/polyrhythmic representation. Polymetric structures are an unsurpassed model for representing musical time and, by extension, the structure of "time objects": music, speech, noise, video, robot movements, etc. This model is able to deal with incomplete definitions and performs all terminal time calculations accurately, using integer ratios. The results are simplified to avoid integer overflow and to match the quantization required for real performance.
Current work
A new version of Bol Processor compatible with 64-bit processors on various systems (MacOS, Windows, Linux…) is currently under development. It works with a PHP/JavaScript interface. We invite software designers to join the team and contribute to the development of the core application and its client applications. Please join the BP open discussion forum and/or the BP developers list to stay in touch with the progress of the work progress and to discuss related theoretical issues.
References
- Time and Musical Structures (1990) on polymetric structures
- Two Algorithms for the Instantiation of Musical Structures (1994) on polymetric structures and the time-setting algorithm of sound objects
- Migrating Musical Concepts: An Overview of the Bol Processor (1998) for a general presentation including a description of quantization.
Contributors to this article: Bernard Bel