The core of the Bol Processor, in all its versions, is an inference engine capable of generating 'items' — strings of variables and terminal symbols — treated like the score of a musical work. The inference engine does this through the use of rules from a formal grammar.
In its initial versions (BP1 and BP2), the inference engine was also able to analyse a score — for example, a sequence of drum beats — to check its validity against the current grammar. This feature is not (yet) implemented in BP3.
A brief presentation of grammars
The grammars used by the Bol processor are similar to those described in formal language theory with a comprehensive layout:
- Rules can be context-sensitive, including with remote contexts on the left and the right.
- Rules can contain patterns of exact or pseudo repetitions of fragments. Pseudo repetitions make use of transformations (homomorphisms) on the terminal symbols.
- A terminal symbol represents a time object which can be instantiated as a simple note or a sound object, i.e. a sequence of simple actions (MIDI messages or Csound score lines).
- The grammars are layered — we call them 'transformational'. The inference engine first does everything it can with the first grammar, then jumps to the second, and so on.
The “produce all items” procedure
Grammars can produce infinite strings of symbols if they contain recursive rules. This is of no practical use in the Bol Processor, as it will eventually lead to a memory overflow. When recursive rules are used, control is exercised by dynamically decreasing rule weights or using 'flags' to invalidate recursivity.
This means that the machine only generates finite languages within its technical limitations. Theoretically, it should be able to enumerate all productions. This is the aim of the "produce all items" procedure. In addition, identical items are not repeated; to this effect, each new item is compared with the preceding ones.
For geeks: This is done by storing productions in a text file which is scanned for repetitions. The efficiency of this method depends on the technology of the working disk. A SSD is highly recommended!
A simple example
Let us start with a very simple grammar "-gr.tryAllItems0" which is made up of two layers of subgrammars:
-se.tryAllItems0
-al.abc
RND
gram#1[1] S --> X X X
gram#1[2] S --> X X
-----
RND
gram#2[1] X --> a
gram#2[2] X --> b
The RND instruction indicates that the rules in the grammar will be selected randomly until no rule applies. The first subgrammar produces either "X X X" or "X X", then the machine jumps to the second subgrammar to replace each 'X' with either 'a' or 'b'.
In the " Produce all items" mode, rules are called in sequence, and their derivations are performed by picking up the leftmost occurrence of the left argument in the work string.
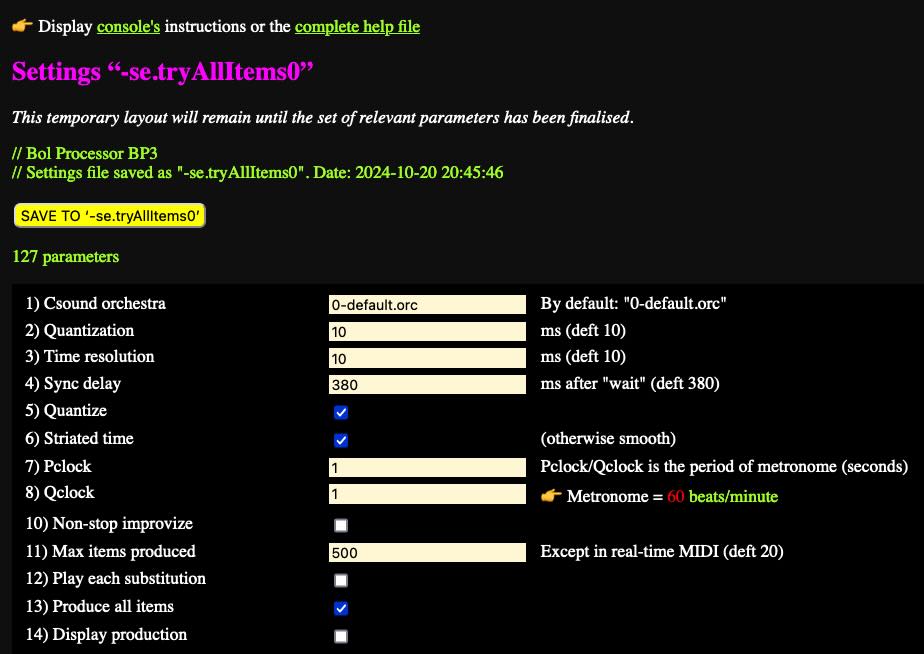
In the settings of " tryAllItems0 " (see picture), "Produce all items" is checked. A parameter " Max items produced" can be used to limit the number of productions.
The output is set to "BP data file" for this demo, although real-time MIDI, MIDI files and Csound score are possible because 'a' and 'b' are defined as sound-objects. However, the sound output is completely irrelevant with this simple grammar.
Any production that still contains a variable is discarded. This never happens with the " tryAllItems0 " grammar.
The production of this grammar is:
a a a
a a b
a b a
a b b
b a a
b a b
b b a
b b b
a a
a b
b a
b b
All the steps are shown on the self-explanatory trace:
A pattern grammar
Let us modify "-gr.tryAllItems0" as follows:
-se.tryAllItems0
-al.abc
RND
gram#1[1] S --> (= X) X (: X)
gram#1[2] S --> X X
-----
RND
gram#2[1] X --> a
gram#2[2] X --> b
The first rule gram#1[1] contains a pattern of exact repetition: the third 'X' should remain identical to the first one. Keeping the pattern brackets, the production would be:
(= a) a (: a)
(= a) b (: a)
(= b) a (: b)
(= b) b (: b)
a a
a b
b a
b b
This output shows that the third terminal symbol is a copy of the first. These items can be played on MIDI or Csound, as the machine will remove structural markers. However, structural markers can also be deleted on the display by placing a " _destru" instruction under the "RND" of the second subgrammar. This yields
a a a
a b a
b a b
b b b
a a
a b
b a
b b
To become more familiar with patterns (including embedded forms), try "-gr.tryDESTRU" in the "ctests" folder.
A more complex example
Consider the following grammar "-gr.tryAllItems1" in the "ctests" folder:
RND
gram#1[1] S --> X Y /Flag = 2/ /Choice = 1/
-----
RND
gram#2[1] /Choice = 1/ /Flag - 1/ X --> C1 X
gram#2[2] /Choice = 2/ X --> C2 X _repeat(1)
gram#2[3] <100-50> /Choice = 3/ X --> C3 X
gram#2[4] X --> C4 _goto(3,1)
gram#2[5] Y --> D3
Gram#2[6] X --> T
-----
RND
gram#3[1] T --> C5 _failed(3,2)
gram#3[2] Y --> D6
This grammar uses a flag 'Choice' to select which of the rules 1, 2 or 3 will be used in subgrammar #2. Just change its value to try a different option, as they produce the same 'language'. Terminals are simple notes in the English convention: C1, C2, etc.
The flag 'Flag' is set to 2 by the first rule. If 'Choice' is equal to 1, rule gram#2[1] is applied, and it can only be applied twice due to the decrementation. This ensures that the language will be finite.
Rule gram#2[4] contains a "_goto(3,1)" instruction. Whenever it is fired, the inference engine will leave subgrammar #2 and jump to rule #1 of subgrammar #3. If the rule is a candidate, it will be used and the engine will continue to look for candidate rules in subgrammar #3. If the gram#3[1] rule is not applicable, the engine will jump to rule #2 of subgrammar #3, as instructed by "_failed(3,2)". In fact, these _goto() and _failed() instruction have no effect on the final production, but they do modify the trace.
If 'Choice' is equal to 2, the " _repeat(1)" instruction will force the gram#2[2] rule to be applied two times. If 'Choice' is equal to 3, the rule gram#2[3] will be applied twice because it has an initial weight of 100 which is reduced by 50 after each application. When it reaches zero, the rule is neutralised.
For all values of 'Choice' the production is:
C1 C1 C4 D6
C1 C1 C4 D3
C1 C1 C5 D3
C1 C1 C5 D6
C1 C4 D6
C1 C4 D3
C1 C5 D3
C1 C5 D6
C4 D6
C4 D3
C5 D3
C5 D6
Since you insist, here is the output played in real time on a Pianoteq instrument!
We hope for more convincing musical examples. 😀