The "learning rule weights" feature was implemented in the first version of the Bol Processor (BP1) a long time ago. It was designed in response to a problem that arose during fieldwork sessions while Jim Kippen was developing grammars capable of identifying the "language" conveyed by qa‘ida compositions of tabla. Citing Jim (Kippen & Bel, 1992):
[…] sometimes a grammar would reach a point of stagnation where computer-generated variations were judged to be neither very good nor incorrect. Consequently there was no simple way of refining or improving the model. We felt that a solution lay in attributing to each production rule a coefficient of likelihood (or weight) where the probability that certain generative paths would be chosen in preference to others could be examined.
The probabilistic model that has been implemented on the BP is derived from probabilistic grammars/automata as defined by Booth & Thompson (1973), the difference being that a weight rather than a probability is attached to every rule. The rule probability is computed as follows: if the weight is zero then the probability is zero; if the weight is positive then the inference engine calculates the sum of weights of all candidate rules, and the rule probability is the ratio of its own weight to the sum.
Rule weights can be inferred from a set of sentences (Maryanski & Booth 1977:525). The algorithm implemented in the BP is more powerful than the one devised by Maryanski and Booth, since the latter required the choice of a sample set in which all rules had been used. Given a grammar and a subset of the language that this grammar generates (for instance a sample sequence taken from a performance of an expert musician), rule weights may be inferred as follows: first, reset all weights to zero. Then, analyse every sentence and increment the weights of all rules used in the derivation by one unit.
We will demonstrate the inference of rule weights using grammars and data distributed in the ‘ctests’ folder. These grammars are real examples from field work.
Infer weights in the "-gr.dhadhatite" grammar
The ‘ctests’ folder contains both "-gr.dhahatite" and "-dha.dhahatite". The latter is a set of 15 examples designed for the demonstration. They are not of great interest because they were all produced by the grammar and will therefore be parsed successfully. However, you can try modifying details to observe failed parsing.
In addition, the first eight ones are identical, except for their notation. Items can be typed without spaces, given that the terminal alphabet "-al.dhahatite" will create a correct segmentation. They can be set out on several lines separated by single line feeds. Beats can be marked with periods (the period notation) which the polymetric algorithm interprets as identical symbolic durations (see this page).
Let us have a look at the "-gr.dhahatite" grammar which we already used for parsing variations. First create its templates as explained earlier.

Open the settings and check the LEARN option for parsing data files (see image). The option "Start from latest weights file instead of grammar" is selected by default and will be explained further.
Then add "-dha.dhahatite" and "-wg.dhahatite" in declarations on top of the grammar, and save the page.
This modifies the display of the top of the grammar:
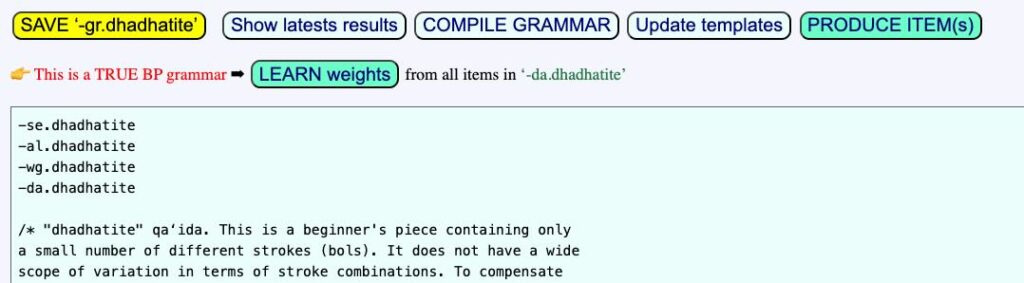
Clicking the LEARN weights button will launch the inference of weights from the sample set in "-dha.dhahatite":
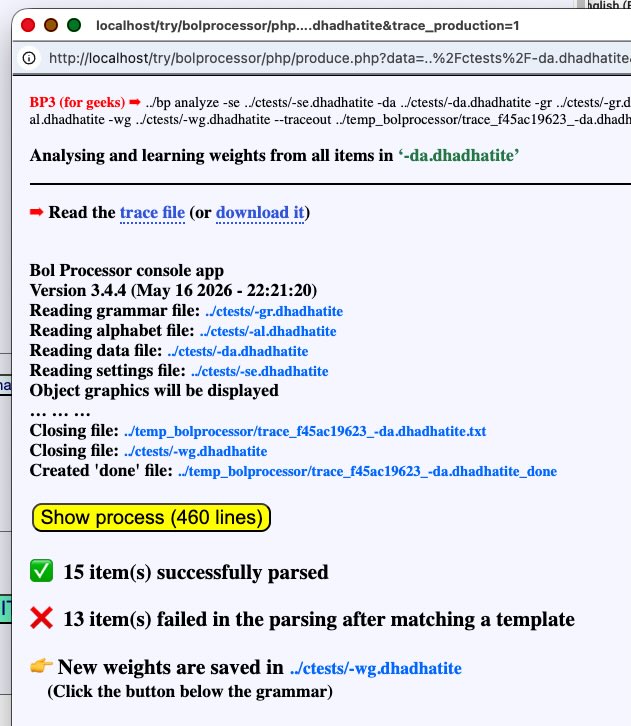
The production window shows that all 15 items were successfully parsed although
"13 item(s) failed in the parsing after matching a template"… We knew that this grammar would accept all items, so we need an explanation for the failed parsing.
Click the Show process button to get more details:
🔎 Analyzing new selection…
dhadhatitedhadhadheenadheenatitedheenateenadhadhatitedhadhadheenadhadhatitedhadhateenatatatitetatateenateenatiteteenateenadhadhatitedhadhadheenadhadhatitedhadhadheena
▶︎ Analyzing item [Single line]
👉 Item [Single line] matched template [1]
• Subgrammar 6/6
• Subgrammar 5/6
• Subgrammar 4/6
• Subgrammar 3/6
• Subgrammar 2/6
• Subgrammar 1/6
Item [Single line] matching template [1] rejected by grammar… ❌
Result of failed analysis:
S1F +V8(= S1F) +S2F *(= S1F ++A2 V6)(: S1F) S1F
👉 Item [Single line] matched template [2]
• Subgrammar 6/6
• Subgrammar 5/6
• Subgrammar 4/6
• Subgrammar 3/6
• Subgrammar 2/6
• Subgrammar 1/6
Item [Single line] matching template [2] rejected by grammar… ❌
Result of failed analysis:
(= ++S2F) +V8 S1F +S2F *(: ++S2F) *(= ++A2 V6) S1F S1F
👉 Item [Single line] matched template [3]
• Subgrammar 6/6
• Subgrammar 5/6
• Subgrammar 4/6
• Subgrammar 3/6
• Subgrammar 2/6
• Subgrammar 1/6
Item [Single line] matching template [3] accepted by grammar… ✅
Etc.
This report shows that the first item failed to match two templates but was later correctly parsed after matching template [3]. Other items displayed similar behaviour. At the top of the page, there is a link to a trace of the parsing because the "Trace production or parsing" option is selected in the settings. There is also a "Detailed trace" option available for automated analysis, which is not discussed here.

Now, move down to the bottom of the grammar and click the "-wg.dhadhatite" button. This file was created by the BP3 console upon completion of its analysis. It contains the new weights of the grammar, i.e. for each rule, the original weight (usually 100) plus the number of times the rule has been used in the parsing process.
For example, the weight of rule [1] of gram#1 would be raised from 100 to 115, since it was used for all 15 items. However, the weight of rule [5] of gram#1 would stay at 100, since it was not used in this analysis. Changes are easy to check comparing the content of "-wg.dhadhatite" with weights in the grammar.
The "-wg.dhadhatite" display includes several buttons that are easy to understand:
- The COPY current weights button will copy all the weights in the grammar to the file "-wg.dhadhatite";
- The SET rule weights and RESET rule weights buttons will set or reset all weights in the file "-wg.dhadhatite", yet not in the grammar.
- The COPY BACK rule weights button will copy weights from "-wg.dhadhatite" to the "-gr.dhadhatite" grammar. Then you are offered the option to save the grammar if these weights are correct, or to reload the grammar otherwise:

- The "-wg.dhadhatite" page also has buttons that allow you to save a copy of its weights to a new '-wg' file, or copy weights from another file.
In real life…
This "-wg.dhadhatite" layout shows how to proceed in real-life situations. You have a working Bol Processor grammar, as well as large sets of examples produced by the grammar and validated (or provided) by the expert you are working with. Proceed as follows:
- Open the "-wg" file and RESET all weights to 0 (in that file);
- Click the LEARN weights button;
- Keep an eye on items that are rejected. These may indicate an incomplete grammar. They may also be incorrect. If so, make changes and go back to step 1;
- If the option "Start from latest weights file instead of grammar" is selected, you can repeat this process with more sets of examples, as rule weights will add up.
Although rule weights can be very large integers, we find it more practical to keep them within a small range, such as 0 to 127. The 127 limit is just a convention that can be changed in the PHP interface. Currently, if the weight of a rule is not displayed, its value is 127, and vice versa.
References
Kippen, Jim, & Bernard Bel (1992) Modelling music with grammars: formal language representation in the Bol Processor. In A. Marsden & A. Pople (eds.): Computer Representations and Models in Music, London, Academic Press, 1992, p. 207-238.
Booth, T.L. and R.A. Thompson (1973). Applying Probability Measures to Abstract Languages, IEEE Transactions on Computers, Vol. C-22, n°5, p. 442-450.
Maryanski, F.J., and T.L. Booth (1977). Inference of Finite-State Probabilistic Grammars, IEEE Transactions on Computers, Vol. C-26, n°6, p. 521-536.
[Some anomalies of this paper are corrected in B.R. Gaine's paper Maryanski's Grammatical Inferencer, IEEE Transactions on Computers, Vol. C-27, n°1, 1979: 62-64]