The Bol Processor can analyse musical variations (strings of terminal symbols) using a grammar. A successful parse (membership test) indicates that the variation was produced by, or could be produced by, the grammar. This process was used extensively for modelling improvisation and composition in north Indian tabla drumming — read Jim Kippen's interview.
On this page we will introduce the real data sets "-da.dhahatite" versus "-gr.dhahatite", and "-da.dhin--" versus "-gr.dhin--". However, let us first deal with a very simple example.
A simple true Bol Processor grammar
Grammar "-gr.tryAllItems0" in the "ctests" folder:
RND
gram#1[1] S <-> (= X) X (: X)
gram#1[2] S <-> X X
-----
RND
gram#2[1] X <-> a
gram#2[2] X <-> b
This grammar is a "true Bol Processor grammar":
- It does not contain erase rules such as X --> lambda;
- Rules can be used for producing and parsing items, as indicated by the "<->" derivation sign;
- Rules do not contain any /flag/;
- Rules do not have decreasing weights such as "<K3-20>", "<100-50>", etc.;
- Rules do not contain any procedure such as "_goto", "_repeat", "_destru", etc.;
- Note, however, that rules can contain left/right contexts, including remote ones.
This can be summarised by the following, less technical yet highly relevant statement: a true Bol Processor grammar will deterministically parse every item it can produce. The "deterministic" property means that the algorithm will not backtrack if there are no available candidate rules. This is a fundamental feature of recognising formal languages that represent sets of musical variations.
When a grammar is read, the interface checks whether it is "true BP". If so, a "Create templates" button is displayed.
(For geeks)The interface uses the is_true_bp() function to check the grammar.
This grammar uses the terminal alphabet "-al.abc" which is linked to a set of sound-objects, but we won't use this feature here. Set the output mode to "BP data file".
Let us first produce all items, i.e. the language of this grammar. In the settings, check "Produce all items" in the PRODUCTION section. You can set "Max items produced" to a large number, for instance 500, as we assume that the actual size of the language is much smaller.
Click "PRODUCE". The result is:
a a a
a b a
b a b
b b b
a a
a b
b a
b b
The first four items have been created by gram#1[1], the first rule of the first subgrammar. The rule contains a pattern (=X)…(:X) meaning that the first and last parts must be identical.
The gram#1[2] rule produces two instances of variable X that are rewritten as 'a' or 'b' in gram#2. All possibilities are displayed in the last four items.
These 8 items have been copied to "-da.tryAnalyse", with additional empty lines to separate them.
Parse "-da.tryAnalyse"
In order to parse items in "-da.tryAnalyse", we need to write the name of the grammar on top of the Data page, along with links to the alphabet and settings:
-se.tryAnalyse
-al.abc
-gr.tryAllItems0

Now, "Analyse" buttons are shown for each item. However, if you click on any of these, the parsing will fail for the first four. The reason is that these should be recognised by gram#1[1], which is a pattern rule. In other words, we need to tell the engine that the pattern has been recognised.
👉 This is why we need to create templates in true BP grammars that contain pattern rules.
Create templates for "-gr.tryAllItems0"
Click the "Create templates" button, then click the "output file" link. We get:
----------
TEMPLATES:
[1] (@0 _)_(@1 )
[2] _ _
---------
In this simple grammar, the two templates represent the pattern types of each rule in gram#1. Although no theoretical knowledge of templates is required to use them, let us have a little explanation:
Template [2] contains two occurrences of '_', which means it will match any item containing two terminal symbols.
Template [1] contains the structural markers "@0" indicating a master parenthesis, and "@1" its slave copy. Note that "@0" is followed by a single "_", indicating a single terminal symbol, but "@1" is alone in its parenthesis, as it is meant to be the exact copy of its master.
Copy the templates, paste them at the bottom of grammar "-gr.tryAllItems0", then save the grammar. Note that the template button now appears as "Update templates".
Parse "-da.tryAnalyse" using the templates in "-gr.tryAllItems0"
Return to the "-da.tryAnalyse" and click the "Analyse" buttons. Now, all items are parsed successfully. The trace of the analysis of the first item "a a a" make it clear:
Analysing this item
Compiling grammar…
Compiling subgrammar #1…
Compiling subgrammar #2…
Compiling subgrammar #3…
Parsing completed
Errors: 0
Template(s) found, position 333
👉 We will try all templates, as per your settings
Analyzing selection…
Item matched template [1]
• Subgrammar 3/3
• Subgrammar 2/3
• Subgrammar 1/3
👉 Item matching template [1] accepted by grammar… ✅
Evidently, the four first items will match the "template [1]", and the four last items will match the "template [2]". The trace is self-explanatory:
Selected: gram#2[1] X <-> a
(= a) X(: a)
Selected: gram#2[1] X <-> a
(= X) X(: X)
Selected: gram#1[1] S <-> (= X) X(: X)
S
A few words about the creation of templates. Firstly, this procedure is restricted to finite languages. A grammar containing recursive rules would produce items of unrestricted length, resulting in an infinite number of templates. The Bol Processor has grammar procedures, such as "_repeat()", that tell the number of times a rule can be applied, thereby limiting the length or duration of any production. However, these procedures are currently not applicable to the parsing of items.
Secondly, at first glance, creating templates for the simple grammar amounts to producing the entire language, replacing terminals with '_', and eliminating duplicate instances. This would be impractical for most real-world grammars because, although the language is finite, it can be very large. To avoid this, the machine first determines up to which subgrammar structural rules are found. Then it explores all derivations of these subgrammars, and for each derivation it produces only one item which is converted to its template.
Structural rules are the ones that contain syntactic structures (master-slave parentheses) or/and structural markers if they are not in the contexts of the rule.
Structural markers are the glyphs '+', ':', ';', '=' and '\'. We'll see their usage in grammars for tabla compositions.
Analysis of "-da.acceleration" (without templates)
The "-gr.acceleration" grammar has no template, but you can check that it is able to parse "-da.acceleration" which it had created. Note that all rules have '<->' derivation signs instead of '-->' as in the old version.
A particular feature of this grammar is that a rule contains a period (beat marker) :
gram#1[2] A <-> E2 •
The item produced by this grammar contains periods that create the accelerating tempo:
_transpose(12) _vel(60) E2 • D2 E2 • _vel(65) B2 D2 E2 • G2 B2 D2 E2 • _vel(70) F#2 G2 B2 D2 E2 • Bb2 F#2 G2 B2 D2 E2 • _vel(75) C2 Bb2 F#2 G2 B2 D2 E2 • _vel(77) G#2 C2 Bb2 F#2 G2 B2 D2 E2 • _vel(80) A2 G#2 C2 Bb2 F#2 G2 B2 D2 E2 • _vel(85) Eb2 A2 G#2 C2 Bb2 F#2 G2 B2 D2 E2 • _vel(87) C#2 Eb2 A2 G#2 C2 Bb2 F#2 G2 B2 D2 E2 • _vel(90) F2 C#2 Eb2 A2 G#2 C2 Bb2 F#2 G2 B2 D2 E2 •
These periods are taken into account for the analysis because they have been produced by the grammar. For example, if you erase the last one, the parsing will fail.
Performance controls such as "_transpose()" and "_vel()" are ignored. The trace of the (successful) parsing ends as follows:
…
Selected: gram#1[3] B <-> D2 A
E2 . B C D E F G H I J K L
Selected: gram#1[2] A <-> E2 .
A B C D E F G H I J K L
Selected: gram#1[1] S <-> A B C D E F G H I J K L
S
Remember that "." and "•" are identical glyphs on BP3.
Rule selection criteria
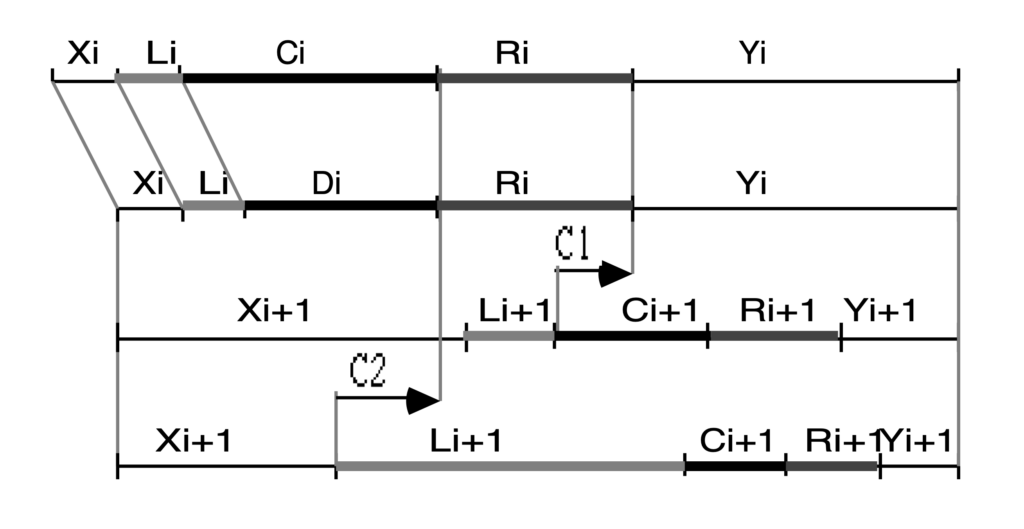
To ensure the deterministic analysis is successful, several rules and selection criteria must be observed.
When multiple rules are candidates for rewriting a string Wi, the system selects based on:
- (D1) Position: Preference for the rightmost possible derivation.
- (D2) Context Length: Preference for the rule that maximizes the fulfillment of context conditions.
- (D3) Pattern Length: "Priority to the largest aggregates of symbols." Longest patterns are recognized first.
- (D4) Order: The reverse order of appearance in the grammar.
To prevent ambiguity and "checkmate" scenarios in analysis, the following rules are applied:
- The Chunk Rule: The right-hand side of a rule fi cannot be a substring of the right-hand side of a rule fj where j < i.
- The Context Rule: In a LIN subgrammar, a right-hand context can only contain symbols from the subgrammar's external alphabet. Every symbol in the external alphabet of a subgrammar Gi is a terminal of a subgrammar Gj with j < i.
Explanations and proofs are found in chapter 4 of Bel's (1990) thesis: French and (bad English) versions.
Analysis of tabla compositions
Grammars "-gr.dhahatite" and "-gr.dhin--" are authentic examples of qa‘ida, the basic composition/improvisation form in the Lucknow school of tabla, as taught to Jim Kippen by Ustad Afaq Husain Khan in the early 1980s. (Read our joint paper in Anthropological Quarterly, 1989.)
The methods described here were first implemented in 1981 on an Apple IIc computer with just 64 kilobytes of memory… The Bol Processor BP1 was programmed in 6502 assembly language. Still, it was efficient enough to be used as an expert system for field research with leading exponents of the tabla.
The Bol Processor grammar concept emerged from formulating hypotheses about the structures of a qa‘idas within a teaching context. The aim was to generate as many variations as possible that would be deemed correct by an expert. However, proper identification of the language implied that the machine would be able to recognise good and bad variations submitted by experts and students alike. For this reason, each grammar should work "in reverse": given a musical variation (a string of terminals typed on the keyboard), the rules are applied from bottom to top until no rule remains applicable. If the final symbol is "S", the starting symbol, then the musical variation is assessed as "correct".
The "-gr.dhadhatite" grammar
The "dhadhatite" qa‘ida is taught to tabla beginners. This is because it is technically easy while also following complex syntactic structures, which traditional musicians refer to as "qavaid" — a term meaning "grammar" in Urdu (and Arabic). Therefore, the idea of using formal grammars to describe this compositional type was very promising.
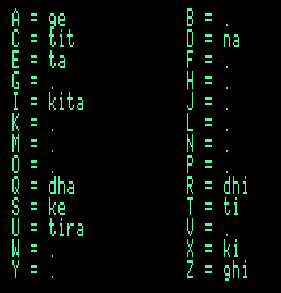
The Bol Processor enables users to program the computer's keyboard to map words to keys instead of characters. For example, typing "q" on an English keyboard would type "dha" into the text.
This is possible in "-gr.dhahatite" and "-da.dhadhatite" because "-kb.dhadhatite" is declared at the top of the grammar or data. The mapping is effective after pressing the "escape" key — read details.
When you open the "-gr.dhahatite" grammar, you will see that it is recognised as a "true BP grammar". Click the "Create templates" button, click the "output file" link, and copy the templates at the bottom of the grammar:
TEMPLATES:
[1] ________+________(@0 ________)+________ * (@0 ________++________)(@2 )________
[2] (@0 ++________)+________________+________ * (@1 ) * (@0 ++________)________________
[3] ________(@0 ______+__)________+________ * (@0 ________) * (@2 )________________
[4] (@0 ++____________+____)________+________ * (@1 )________________
[5] (@0 ++______________+__)________+________ * (@1 )________________
[6] (@0 ++________________)________+________ * (@1 )________________
These six templates contain markers of master-slave parentheses created by subgramar #2, including markers of a homomorphism, notated "*", that modifies the content of the following parenthesis, applying a mapping defined in the "-al.dhadhatite" alphabet:
*
dha --> ta
ti
te
na
dhee --> tee
tr
The terminal alphabet of this grammar is made of sound-objects named "dha", "ta", etc. These are quasi-onomatopoeic mnemonics, in an oral notation system, that represent drum-strokes. The "*" homomorphism reflects the musical concept of replacing "open" (resonating) strokes, such as "dha" and "dhee", with their "closed" counterparts, here "ta" and "tee". So, for instance "*(dhadhatite)" should be played "tatatite". You can use any word you like instead of "*" to label the mapping.
The templates also contain structural markers "+" also produced by subgrammar #2, for example:
gram#2[1] S1F S2F S1V S2F E32 <-> S1F +S2F (= V8) +S2F * (= S1F ++ S2F) (: V8) S1F
These markers are used as (proximate) contexts in subgrammar #5, for example:
gram#5[5] ++ A2 <-> ++dheena
gram#5[6] #+ S1F <-> #+ dhadhatitedhadhadheena
In rule [5], the string "++" is a left context, but in rule [6] the string "#+" is a negative context, meaning anything but '+'.
The last rule of subrammar #5 deserves our attention:
gram#5[8] ++ S2F <-- ++ dhadhatitedhadhadheena
It is using the derivation sign "<--" instead of "<->". This means that this rule can only be used in the analysis. It is easy to guess that when the sequence of strokes "dhadhatitedhadhadheena" is found preceded by a "++" (picked up from the template), it is immediately identified as "S2F". Sequences S1F and S2F appear in typical rhythmic contexts shown in subgrammar #1, for example:
gram#1[3] S64 <-> S1V S2F S1F S2F E32
In subgrammar #2, some of these fixed units are replaced with variations:
gram#2[2] S1V S2F S1F S2F E32 <-> (=++ A1 V7 ) +S2F S1F +S2F * (:++ A1 V7 ) * (= ++ S2F ) S1F S1F
To make things easier, the analyst labelled the variables with numbers indicating their durations: 1 for A1, for example, and 7 for V7. This is not compulsory, however.
In subgrammar #3, variations are broken down into smaller units. For example:
gram#3[18] V7 <-> T1 V6
gram#3[19] V7 <-> T2 V5
Then in the following subgrammars, small units are rewritten as sequences of strokes, for instance:
gram#4[5] T2 <-> dheena
…
gram#5[2] + B4 <-> +dhadhateena
Experts familiar with this musical genre will be convinced by an in-depth analysis of this grammar and experiments of production that its construction is based on musical concepts that are embodied perfectly in the formal grammars of the Bol Processor.
There is little to say about the derivation modes of these subgrammars. Most of them could be set to "RND", but "LIN" produces equivalent output in less computation time. This was critical in the Apple II era… Subgrammar #5 is "ORD", the fastest option, but "LIN" or "RND" would also be acceptable.
Now, let us produce a few variations of the "-gr.dhahatite" grammar. In the settings, check the "Non-stop improvize" option and set "Maxitems produced" to a small number, e.g. "4"., which is safe in terms of computation time and disk usage. Set the output file to "BP data file", since no sounds are expected.
If the "Seed for randomization" is set to 0 in the settings, you will get a different sequence each time you click the "PRODUCE ITEM(s)" button, for example:
4+4+4+4/4 dha dha ti te • dha dha dhee na • dha dha dhee na • ti te tee na •
dha dha ti te • dha dha dhee na • dha dha ti te • dha dha tee na •
ta ta ti te • ta ta tee na • ta ta tee na • ti te tee na •
dha dha ti te • dha dha dhee na • dha dha ti te • dha dha dhee na4+4+4+4/4 dha dha tee na • dha dha dhee na • dha dha ti te • dha dha tee na •
dha dha ti te • dha dha dhee na • dha dha ti te • dha dha tee na •
ta ta tee na • ta ta tee na • ta ta ti te • ta ta tee na •
dha dha ti te • dha dha dhee na • dha dha ti te • dha dha dhee na4+4+4+4/4 dha dha ti te • dha dha dhee na • dhee na ti te • dhee na tee na •
dha dha ti te • dha dha dhee na • dha dha ti te • dha dha tee na •
ta ta ti te • ta ta tee na • tee na ti te • tee na tee na •
dha dha ti te • dha dha dhee na • dha dha ti te • dha dha dhee na4+4+4+4/4 dha dha ti te • dha dha dhee na • dha dha ti te • dha dha tee na •
tee na dhee na • dha dha ti te • dha dha ti te • dha dha tee na •
ta ta ti te • ta ta tee na • ta ta ti te • ta ta tee na •
tee na dhee na • dha dha ti te • dha dha ti te • dha dha dhee na
The "4+4+4+4/4" sections marking at the start of each variation indicates a layout most suitable for musicians: the beats are separated by periods ("." or "•"), with each beat containing four strokes — hence the "/4". These periods will be ignored in the parsing because they are not created by any rule in the grammar.
The expression "4+4+4+4" indicates that there are four lines, each containing four beats. As expected, the total duration is 16 beats.
👉 An old, still-valid format for "4+4+4+4/4" is "4+4+4+4*1/4".
Note that if "Split terminal symbols" is unchecked, you get a more compact representation, for instance:
4+4+4+4/4 dhadhatite . dhadhadheena . dhadha-- . titeteena .
dhadhatite . dhadhadheena . dhadhatite . dhadhateena .
tatatite . tatateena . tata-- . titeteena .
dhadhatite . dhadhadheena . dhadhatite . dhadhadheena
There is no guarantee that all variations will be different. Another method that ensures this (at the cost of computation time) is to select "Produce all items" instead of "Non-stop improvize" in the settings. Now, the machine only keeps productions that have not been found in the list before.
Items produced by this grammar can be copied to a Data project, here "-da.dhadhatite". The file in "ctests" contains eight variations. Beware that items should be separated by empty lines, which is automatically the case if you checked "Add lines between items" in the settings of "-gr.dhadhatite". In the settings of "-da.dhadhatite", check "Trace production or parsing", then save the settings and data and click "Analyze" near the first item. The "trace file" displays the detailed process which we won't comment. The "Show process" button displays a summary:
4+4+4+4/4 dhadhatite • dhadhadheena • dheenatite • dheenateena •
dhadhatite • dhadhadheena • dhadhatite • dhadhateena •
tatatite • tatateena • teenatite • teenateena •
dhadhatite • dhadhadheena • dhadhatite • dhadhadheena
Template(s) found
👉 We will try all templates, as per your settings
Analyzing selection…
Interpreting structure…
Expanding polymetric expression…
Using quantization = 10 ms with compression rate = 1
Phase diagram contains 2 lines
👉 Item matched template [1]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [1] rejected by grammar… ❌
Result of failed analysis:
S1F +V8(= S1F) +S2F *(= S1F ++V8)(: S1F) S1F
👉 Item matched template [2]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [2] rejected by grammar… ❌
Result of failed analysis:
(= ++S2F) +V8 S1F +S2F *(: ++S2F) *(= ++V8) S1F S1F
👉 Item matched template [3]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [3] accepted by grammar… ✅
👉 Item matched template [4]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [4] rejected by grammar… ❌
Result of failed analysis:
(= ++S2F V4 +B4) S1F +S2F *(: ++S2F V4 +B4) S1F S1F
👉 Item matched template [5]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [5] rejected by grammar… ❌
Result of failed analysis:
(= ++S2F V6 +B2) S1F +S2F *(: ++S2F V6 +B2) S1F S1F
👉 Item matched template [6]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [6] rejected by grammar… ❌
Result of failed analysis:
(= ++S2F V8) S1F +S2F *(: ++S2F V8) S1F S1F
This summary shows that this variation matches all six templates. However, only one leads to successful parsing, ending with the start string "S". This helps determine the syntactic structure of the musical example, in addition to telling that it is "correct".
The initial beat and tempo expression "4+4+4+4/4" can be ignored. The following versions will also be parsed successfully:
/4 dhadhatite • dhadhadheena • dheenatite • dheenateena •
dhadhatite • dhadhadheena • dhadhatite • dhadhateena •
tatatite • tatateena • teenatite • teenateena •
dhadhatite • dhadhadheena • dhadhatite • dhadhadheenadhadhatite • dhadhadheena • dheenatite • dheenateena •
dhadhatite • dhadhadheena • dhadhatite • dhadhateena •
tatatite • tatateena • teenatite • teenateena •
dhadhatite • dhadhadheena • dhadhatite • dhadhadheenadhadhatitedhadhadheenadheenatitedheenateena
dhadhatitedhadhadheenadhadhatitedhadhateena
tatatitetatateenateenatiteteenateena
dhadhatitedhadhadheenadhadhatitedhadhadheenadhadhatitedhadhadheenadheenatitedheenateenadhadhatitedhadhadheenadhadhatitedhadhateenatatatitetatateenateenatiteteenateenadhadhatitedhadhadheenadhadhatitedhadhadheena
The "-gr.dhin--" grammar
This grammar describes two sets of variations associated with the qa'ida. The first set covers 16 beats, i.e. 96 strokes at a speed of 6 per beat. The second set covers 32 beats, i.e. 192 strokes.
The 16-beat version was taught to Jim Kippen by Ustad Afaq Husain Khan in the 1980s. Within weeks, Jim had learned to identify the "language" of this qa‘ida, meaning that the machine successfully parsed all examples provided by the expert musician. However, at the end of the training, when Afaq Husain Khan played the same qa‘ida in a concert, he deliberately expanded variations to 32 beats. None of these were recognised by the grammar. Therefore, the grammar was adapted to produce 32-beat variations, and its validity was verified by analysing the variations performed at the concert.
Each set is represented by a variable named "S96" or "S192", created by subgrammar #1:
RND
gram#1 [1] <0> S <-> 4+4/6 S96
gram#1 [2] <5> S <-> 4+4+4+4/6 S192
The weights of rules 0 and 5 indicate that the weights of the rules have been inferred from a set of examples, five of which belonged to the 'S192' variant and none of which belonged to the 'S96' variant. Weight inference is explained on this page.
The weights of rules 0 and 5 indicate that the weights of the rules have been inferred from a set of examples, five of which belonged to the 'S192' variant and none of which belonged to the 'S96' variant. We will explain weight inference later.
'S192' and 'S96' are broken down further into fixed or variable blocks in subgrammar #2, which also introduces master-slave parentheses and the open-closed homomorphism notated "*":
RND
gram#2 [1] <5> S192 <-> (= F48 ) (= V24 ) F'24 *(: F48 ) (: V24 ) F24
gram#2 [2] <0> S96 <-> (= V24 ) F'24 *(: V24 ) F24
gram#2 [3] <0> V24 <-> (= V12 ) (: V12 )
gram#2 [4] <1> V24 <-> (= V12 ) *(: V12 )
gram#2 [5] <0> V24 <-> Q24
gram#2 [6] <0> V24 <-> V12 V12
gram#2 [7] <4> V24 <-> B24
gram#2 [8] <0> V12 <-> (= B6 ) *(: B6 )
gram#2 [9] <1> V12 <-> B12
Once again, we see that several weight 0 rules have not been used to analyse the example set. No explanation is required for other subgrammars.
Let's ask the machine to produce randomly 5 variations using this grammar and rule weights to determine their probabilities:
4+4+4+4/6 dhin--dhagena . dha--dhagena . dhatigegenaka . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
dheenedheenagena . dhagenadhin-- . dheenedheenagena . dheenedha-dheene .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
tin--takena . ta--takena . tatikekenaka . teeneteenakena .
taketirakita . tin--takena . tatikekenaka . teeneteenakena .
dheenedheenagena . dhagenadhin-- . dheenedheenagena . dheenedha-dheene .
tagetirakita . dhin--dhagena . dhatigegenaka . dheenedheenagena
4+4+4+4/6 dhin--dhagena . dha--dhagena . dhatigegenaka . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
dhin--dhagena . dha--dhin-- . dheenedheenagena . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
tin--takena . ta--takena . tatikekenaka . teeneteenakena .
taketirakita . tin--takena . tatikekenaka . teeneteenakena .
dhin--dhagena . dha--dhin-- . dheenedheenagena . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . dheenedheenagena
4+4+4+4/6 dhin--dhagena . dha--dhagena . dhatigegenaka . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
dhagenadha-- . dheenedheenagena . dheenedheenagena . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
tin--takena . ta--takena . tatikekenaka . teeneteenakena .
taketirakita . tin--takena . tatikekenaka . teeneteenakena .
dhagenadha-- . dheenedheenagena . dheenedheenagena . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . dheenedheenagena
4+4+4+4/6 dhin--dhagena . dha--dhagena . dhatigegenaka . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
dhagenadha-- . dheenedheenagena . dheenedha-dheene . dhagenadhin-- .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
tin--takena . ta--takena . tatikekenaka . teeneteenakena .
taketirakita . tin--takena . tatikekenaka . teeneteenakena .
dhagenadha-- . dheenedheenagena . dheenedha-dheene . dhagenadhin-- .
tagetirakita . dhin--dhagena . dhatigegenaka . dheenedheenagena
4+4+4+4/6 dhin--dhagena . dha--dhagena . dhatigegenaka . dheenedheenagena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
dhagenadha-- . dheenedheenagena . dhatigegenaka . teeneteenakena .
tagetirakita . dhin--dhagena . dhatigegenaka . teeneteenakena .
tin--takena . ta--takena . tatikekenaka . teeneteenakena .
taketirakita . tin--takena . tatikekenaka . teeneteenakena .
dhagenadha-- . dheenedheenagena . dhatigegenaka . teeneteenakena .
tagetirakita . dhin--dhagena . dhatigegenaka . dheenedheenagena
The variations differ slightly. These subtle differences are intended to create a "poetic" effect for listeners familiar with the "language" of the tabla.
Create 16 templates in the "-gr.dhin--" grammar. You will notice that the first eight cover 16 beats and the next eight cover 32 beats. This indicates that the creation of templates disregards rule weights and takes all rules in order. The same is true when creating variations with the "Produce all items" option.
A set of three 32-beat variations is provided in the "-da.dhin--" Data project. You can check that all these variations are successfully parsed. The parsing of the third item deserves our attention:
dhin--dhagena • dha--dhagena • dhatigegenaka • dheenedheenagena •
tagetirakita • dhin--dhagena • dhatigegenaka • teeneteenakena •
dheenedheenagena • dheenedheenagena • teeneteenakena • teeneteenakena •
tagetirakita • dhin--dhagena • dhatigegenaka • teeneteenakena •
tin--takena • ta--takena • tatikekenaka • teeneteenakena •
taketirakita • tin--takena • tatikekenaka • teeneteenakena •
dheenedheenagena • dheenedheenagena • teeneteenakena • teeneteenakena •
tagetirakita • dhin--dhagena • dhatigegenaka • dheenedheenagena
👉 Item matched template [12]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [12] accepted by grammar… ✅
👉 Item matched template [13]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [13] accepted by grammar… ✅
👉 Item matched template [16]
Subgrammar 6/6
Subgrammar 5/6
Subgrammar 4/6
Subgrammar 3/6
Subgrammar 2/6
Subgrammar 1/6
Item matching template [16] rejected by grammar… ❌
In the settings of "-da.dhin--", the option "When parsing, check all templates" is selected. This means that even after a successful analysis, the machine will try all the other templates. In this example, templates [12] and [13] match the composition and both lead to successful parsing. Therefore, there is a syntactic ambiguity in this piece, which we may see as part of its "poetic" dimension.
These demos highlight an important feature of the Bol Processor which is summarised by the following:
- Every language produced by a true Bol Processor grammar is finite;
- The grammar produces a finite (hopefully small) number of templates;
- The parsing of an item matched against a template is done in a deterministic way;
- Consequently, a true Bol Processor grammar is an identification of its finite language.
These qa‘idas are discussed in detail in our paper Modelling music with grammars (Kippen & Bel, 1992). The paper demonstrates the ability of the model to handle complex structures by taking real examples from the repertoire. It also questions the relevance of attempting to model irregularities encountered in actual performance.
(For geeks) An appendix of our Kippen & Bel (1992) paper explains the process of context-sensitive canonic rightmost derivation which is used for the parsing.
More details are found in Bel (1987) and in chapter 4 of Bel's (1990) thesis: French and (bad English) versions.
👉 We recommend continuing your reading with the "Learning rule weights" page.
References
Kippen, Jim, & Bernard Bel (1992) Modelling music with grammars: formal language representation in the Bol Processor. In A. Marsden & A. Pople (eds.): Computer Representations and Models in Music, London, Academic Press, 1992, p. 207-238.
Bel, Bernard (1987) Grammaires de génération et de reconnaissance de phrases rythmiques Grammars for the production and recognition of rhythmic sentences).
Actes du 6e congrès AFCET/INRIA, Antibes, 1987b: 353-366.